Bitcoin price volatility with ARCH models
Oisín Fitzgerald, March 2021
Introduction
It's January 2021 and Bitcoin price have been breaking all time highs. In this context I wanted to explore statistical methods for estimating and forecasting volatility, in particular autoregressive conditional heteroscedasticity (ARCH) models. Volatility is variation around the mean return of a financial asset. Low volatility implies prices are bunched near the mean while high volatility implies large swings in prices. It is considered a measure of investment risk. For example, we may be convinced Bitcoin will continue to rise in value over the short term but reluctant to engage in speculation if there is significant volatility reducing our chances of being able to buy in and sell at "good" prices (even if there a upward trend). I'll add I'm not an expert on financial markets, and that models and graphs below are coded in R.
# packages
library(data.table)
library(ggplot2)# read in data
# Source: https://www.kaggle.com/mczielinski/bitcoin-historical-data
dt_daily_close <- fread("./bitcoin-daily-close-2012-2020.csv")Bitcoin bull markets
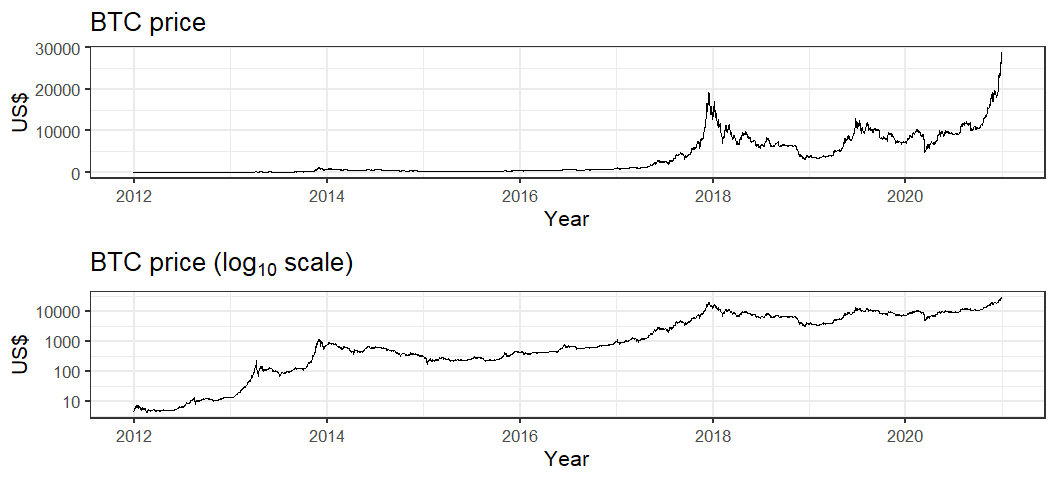
To say the Bitcoin (BTC) price has been going up recently was probably an understatement, the price has gone up more 100% since the beginning of 2020! Although if we compare with previous bull market in late 2017 where the price went up more than 1000% it is not a unique occurrence in Bitcoin's history. Indeed, looking at the graph of Bitcoin on a log scale below we see that the recent (relative) growth rate is comparatively low in Bitcoin's history.
Financial time series basics
It is common in the statistical analysis of financial time series to transform the asset price in order to achieve something closer to a series of independent increments (a random walk). If is the Bitcoin price on day , the daily "log return" is . Using the log differences might seem rather arbitrary at first but it can justified as 1) making a multiplicative process additive and 2) interpretable as the percentage change in asset value. If is the return at time for a starting asset value of then . Taking logarithms gives
Further for small the percentage price is approximately equal to the log return, i.e. . So the random-walk hypothesis hopes that the relative price changes are close to an independent process.
dt_daily_ret <- dt_daily_close[,.(return = diff(log(Close)))]
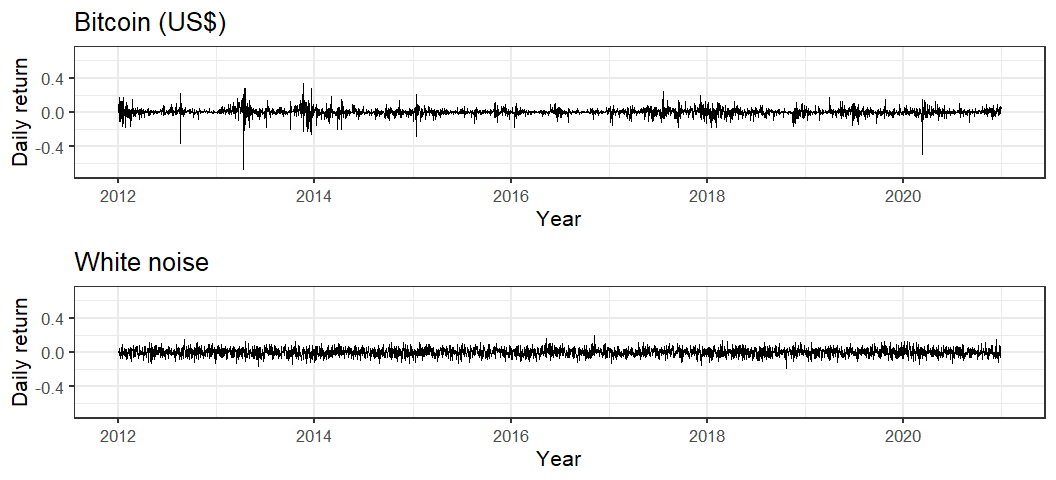
dt_daily_ret[,date := dt_daily_close$date[-1]]We can see in the plot below that appears to be a zero mean process. However, comparing it to a simulated white noise process we see much greater variation in the magnitude of deviations from the the mean. The Bitcoin returns also exhibit clustering in their variance over time. These are characteristics the ARCH model was designed to account for.
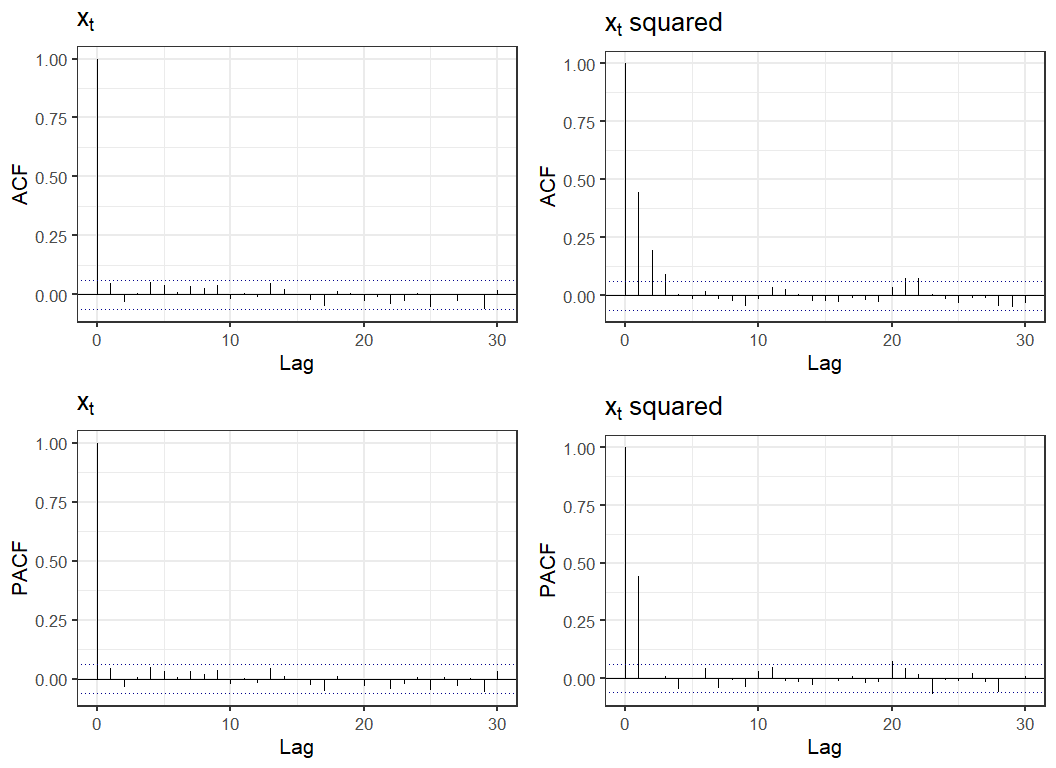
An alternative way to look at a times series is plots of the autocorrelation function (ACF) and partial autocorrelation function (PACF). The ACF graphs the correlation between observations at time and for various values of . Since we average over we are assuming that the series is stationary - intuitively that it's statistical properties don't depend on . The PACF graphs the correlation between and with all intermediate values regressed out. Below are ACF and PACF graphs of the series and . While appears to have relatively weak patterns the ACF and PACF of the process demonstrates clear dependence in the process variance.
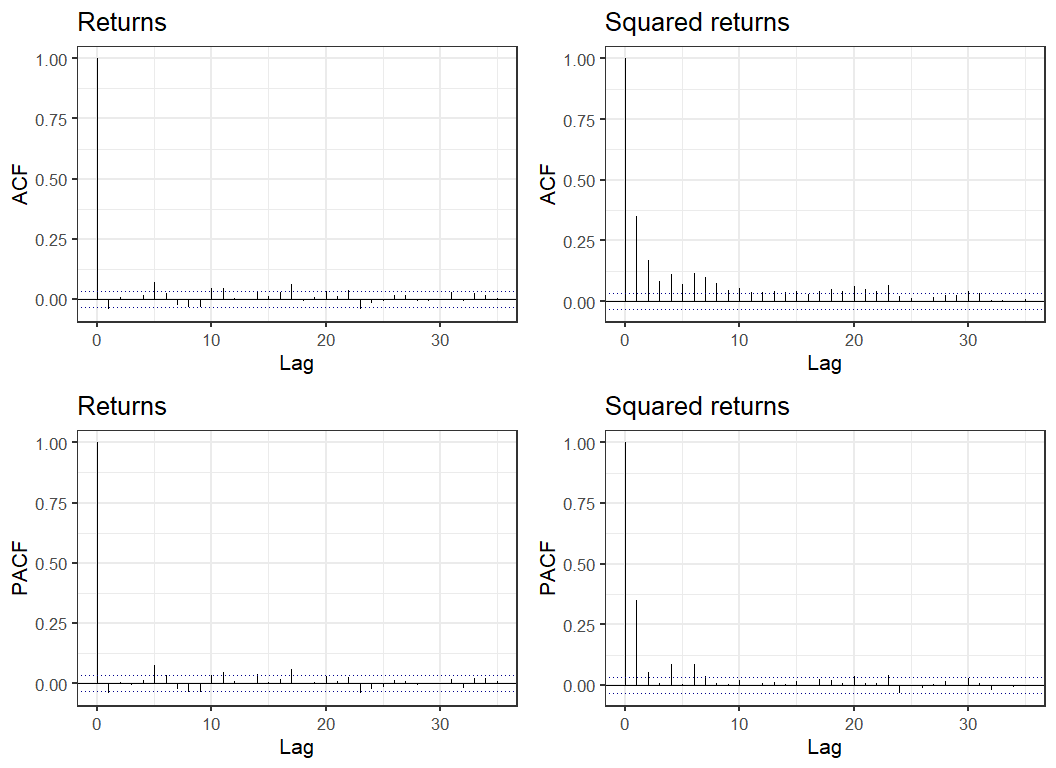
A formal test of independence of a time-series, the Ljung–Box test, strongly rejects independence in with a small p-value. We also reject independence of the increments but this is much weaker signal.
# test of Z_t
Box.test(dt_daily_ret$return,type = "Ljung-Box")##
## Box-Ljung test
##
## data: dt_daily_ret$return
## X-squared = 5.9396, df = 1, p-value = 0.0148# test of Z_t^2
Box.test(dt_daily_ret$return^2,type = "Ljung-Box")##
## Box-Ljung test
##
## data: dt_daily_ret$return^2
## X-squared = 399.32, df = 1, p-value < 2.2e-16Autoregressive conditional heteroscedasticity models
Autoregressive conditional heteroscedasticity (ARCH) models, developed by Robert Engle in 1982, were designed to account for processes in which the variance of the return fluctuates. ARCH processes exhibit the time varying variance and volatility clustering seen in the graph of Bitcoin returns above. An ARCH(p) series is generated as , with and . There have been extensions to the model since 1982 with generalised ARCH (GARCH) and it's various flavours (IGARCH, EGARCH, ...) which allow more complex patterns such as somewhat "stickier" volatility clustering.
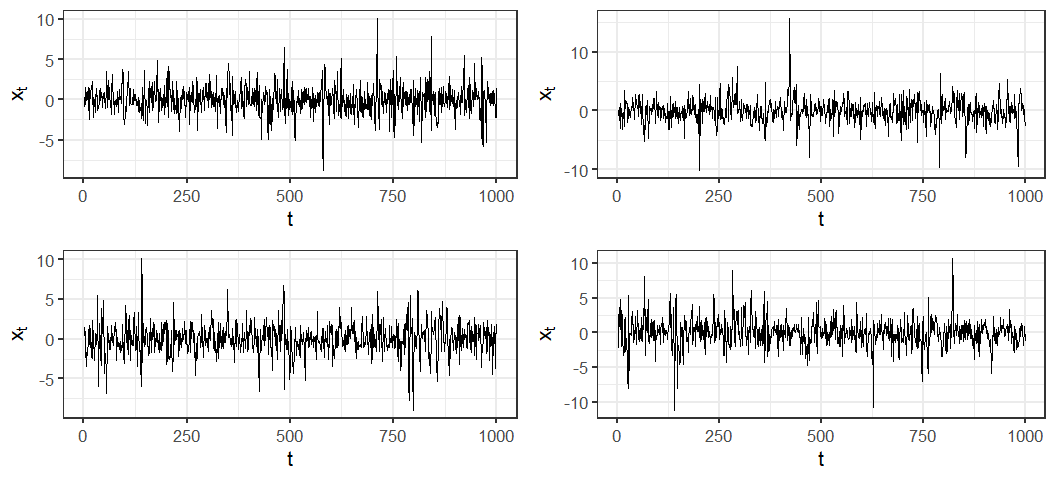
I always like to try and understand how a model works by either simulating form it (for statistical models) or using simulated data to understand it's performance (for machine learning models). Lets simulate some examples of an ARCH(1) process to get an idea of how the simplest version of the process works.
simulate_arch1 <- function(a0,a1,n=1000L) {
# function to simulate an ARCH(1) series
# a0: ARCH constant
# a1: ARCH AR term
# n: length of time series
xt <- numeric(length = n+1)
ee <- rnorm(n+1)
xt[1] <- ee[1]
for (i in 2:(n+1)) {
ht <- a0 + a1*xt[i-1]^2
xt[i] <- ee[i]*sqrt(ht)
}
xt[2:(n+1)]
}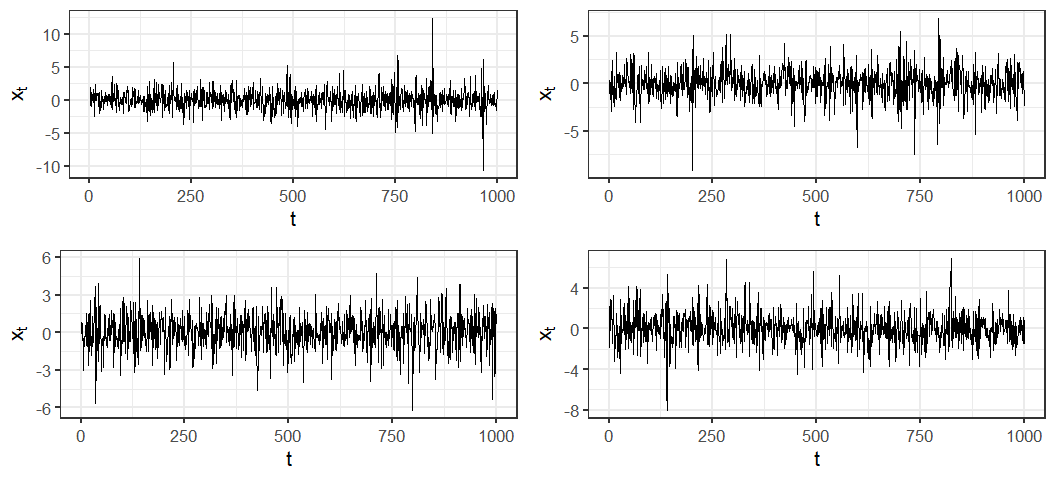
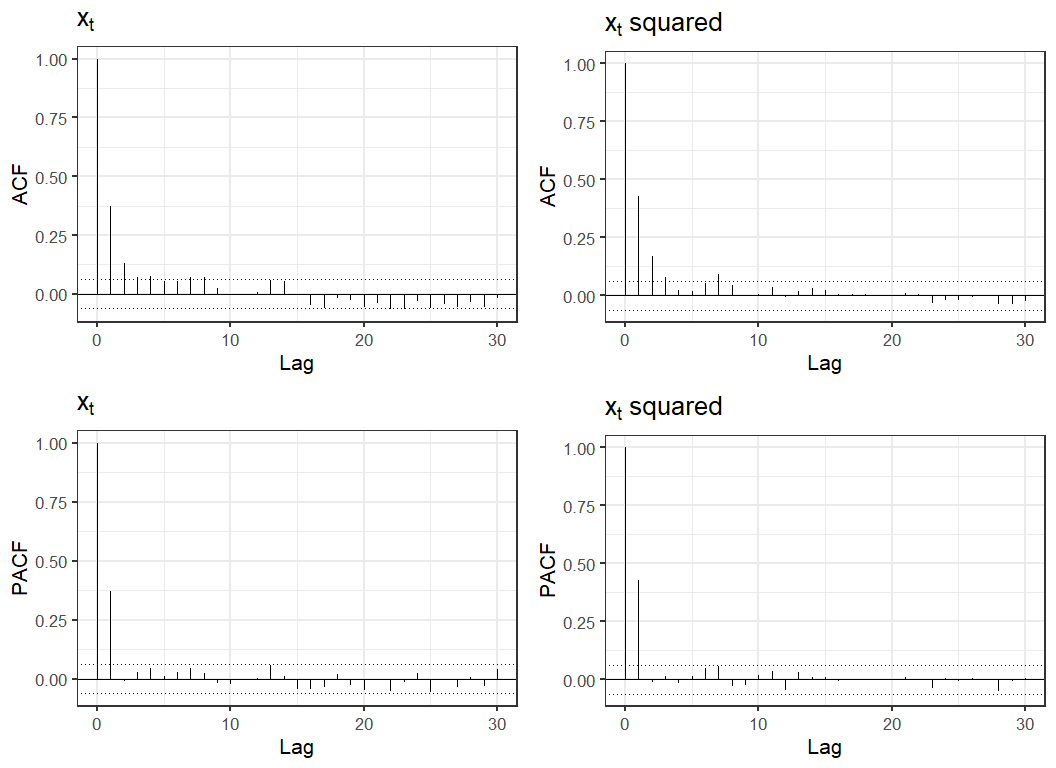
It is worth remembering that ARCH models are for the volatility, we can also have usual trends, or additional ARIMA components. For example, let's simulate an AR(1) model with ARCH(1) volatility, . The plots of the ACF and PACF for this series shows similar correlation patterns for both and .
simulate_ar1_arch1 <- function(u0,a0,a1,n=1000L) {
# function to simulate AR(1) + ARCH(1) series
# u0: autoregressive term
# a0: ARCH constant
# a1: ARCH AR term
# n: length of time series
xt <- numeric(length = n+1)
ee <- rnorm(n+1)
xt[1] <- ee[1]
for (i in 2:(n+1)) {
ht <- a0 + a1*xt[i-1]^2
xt[i] <- u0*xt[i-1] + ee[i]*sqrt(ht)
}
xt[2:(n+1)]
}
Modelling Bitcoin volatility
Now that we've got an idea of how ARCH models work let's move onto modeling Bitcoin returns. We'll use the R package fGarch which estimates the model parameters using Quasi-Maximum Likelihood Estimation. I picked an ARCH(2) model based on a quick comparison of model fit statistics for different values of the heteroscedasdicity order. The garchFit function prints a lot to the console which you can suppress with trace = FALSE.
# fit an ARCH(2) model to Bitcoin returns
library(fGarch)
m1 <- garchFit(~arma(0,0)+garch(2,0),dt_daily_ret$return,trace=FALSE)
summary(m1)##
## Title:
## GARCH Modelling
##
## Call:
## garchFit(formula = ~arma(0, 0) + garch(2, 0), data = dt_daily_ret$return,
## trace = FALSE)
##
## Mean and Variance Equation:
## data ~ arma(0, 0) + garch(2, 0)
## <environment: 0x000001fe0a5c4c30>
## [data = dt_daily_ret$return]
##
## Conditional Distribution:
## norm
##
## Coefficient(s):
## mu omega alpha1 alpha2
## 0.0026455 0.0010569 0.2509526 0.2539785
##
## Std. Errors:
## based on Hessian
##
## Error Analysis:
## Estimate Std. Error t value Pr(>|t|)
## mu 2.645e-03 6.524e-04 4.055 5.02e-05 ***
## omega 1.057e-03 3.843e-05 27.502 < 2e-16 ***
## alpha1 2.510e-01 2.827e-02 8.878 < 2e-16 ***
## alpha2 2.540e-01 3.296e-02 7.705 1.31e-14 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Log Likelihood:
## 5898.152 normalized: 1.796027
##
## Description:
## Thu Jan 21 10:57:27 2021 by user: z5110862
##
##
## Standardised Residuals Tests:
## Statistic p-Value
## Jarque-Bera Test R Chi^2 58727.98 0
## Shapiro-Wilk Test R W 0.8800886 0
## Ljung-Box Test R Q(10) 26.3782 0.003263477
## Ljung-Box Test R Q(15) 39.05692 0.000628423
## Ljung-Box Test R Q(20) 49.41108 0.0002687736
## Ljung-Box Test R^2 Q(10) 14.15045 0.1662389
## Ljung-Box Test R^2 Q(15) 18.71158 0.2271022
## Ljung-Box Test R^2 Q(20) 20.63017 0.4191803
## LM Arch Test R TR^2 15.36755 0.2219489
##
## Information Criterion Statistics:
## AIC BIC SIC HQIC
## -3.589618 -3.582192 -3.589621 -3.586959Calling summary on the resulting model object returns estimates of the model parameters and Ljung–Box statistics for the residuals and squared residuals. The model returned is with . Notice that the Ljung-Box test is significant for the residuals but not squared residuals. The p in Q(p) of the Ljung-Box test results indicates the extent of the autocorrelation lag used in testing for independence of the residuals. So there is evidence of unaccounted for correlation in the data when considering lags up to 15 and 20. However, the ACF and partial ACF suggest that the remaining auto correlation is somewhat complex and weak enough to ignore for the purposes of illustrating basic volatility forecasting with ARCH model.
Rolling probabilitic forecast
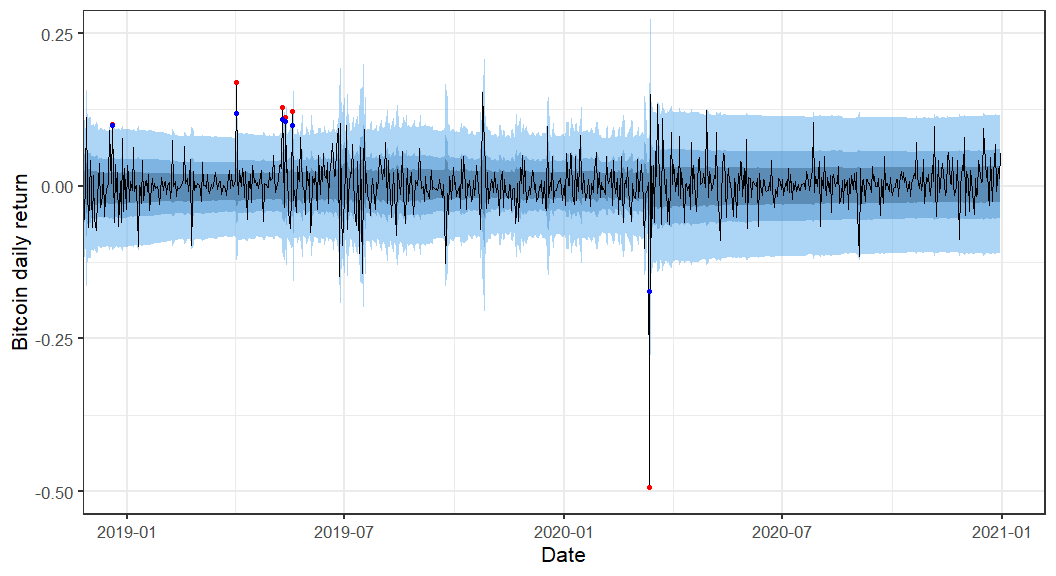
One use of such a model may be to forecast the one day ahead distribution of returns. Our forecasts are of the form . These forecasted distributions can be used to assess the probability of price movements of a particular size. Since we might believe the parameters of the model are not constant I'll use a rolling forecast window of 300+1 days. So starting at day 301 (2012-10-26) until the final day 3,285 (2020-12-31) I'll fit an ARCH(2) model to the previous 300 days and forecast forward one day. We can see in the results that there is considerable room for improvement, the model fails to capture many of the large price movements, but that it is not producing complete nonsense either.
Assessing the forecasts
A more thorough evaluation of the forecasts involves assessing their calibration and dispersion (I won't go into details on this aspect, see for example Gneiting and Katzfuss (2014)). From the graphs below we see that our forecasts are poorly calibrated - the forecasted probabilities of price movement are not reliable. They are likely to over estimate the probability of a large price movement (overdispersion).
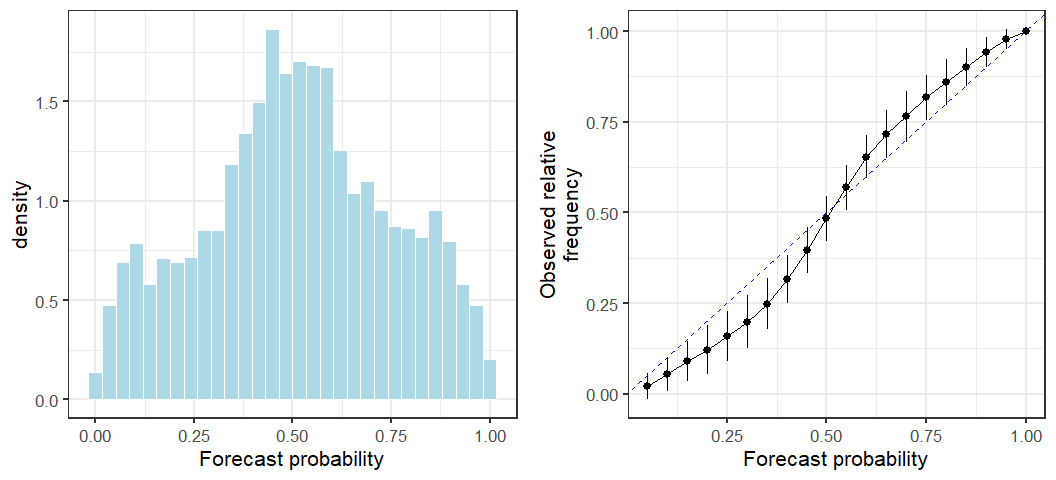
We might wonder whether the poor performance came about due to the large drop in March 2020 influencing future predictions. However, this doesn't appear to be the case. The prediction strategy I used is simply not good!
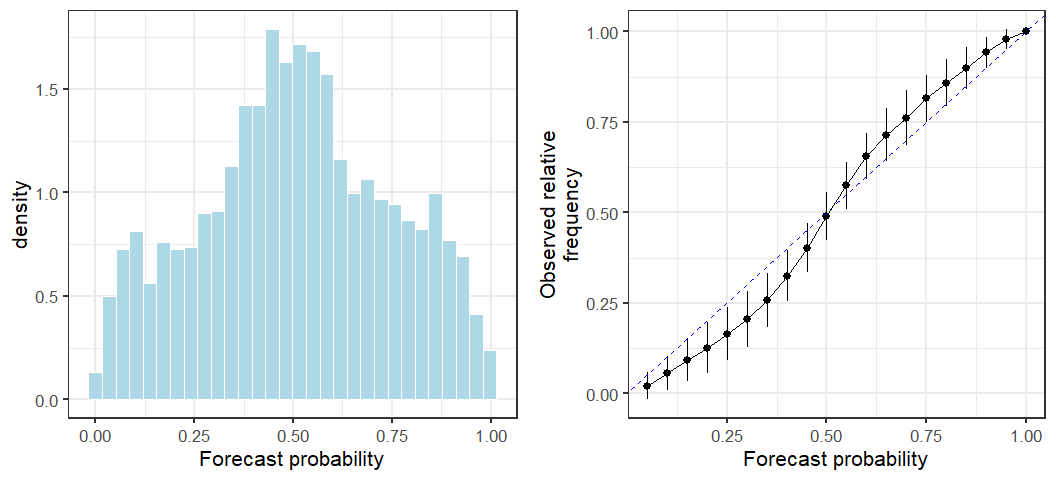
That's all!
Thanks for reading. This was a relatively simplistic introduction to the use of ARCH models for forecasting volatility in the Bitcoin market. ARCH models allow the variance of time series at time to depend on the variance of previous terms , analogous to how autoregressive models. This allows us to forecast distributions of future prices in a manner that is more reflective of empirical observations of financial time series.
Reading and links
Gneiting, T., & Katzfuss, M. (2014). Probabilistic forecasting. Annual Review of Statistics and Its Application, 1, 125-151.
Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica: Journal of the Econometric Society, 987-1007.
Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 31(3), 307-327.
Data source: https://www.kaggle.com/mczielinski/bitcoin-historical-data
fGarch R package: https://cran.r-project.org/web/packages/fGarch/fGarch.pdf